

Velké jazykové modely, často označované zkratkou LLM (z anglického Large Language Model), jsou moderní typy systémů umělé inteligence navržené ke zpracování, porozumění a generování textu v přirozeném jazyce. Konkrétně se jedná o podtyp AI technologie v rámci Deep learning (hlubokého učení), který se zaměřuje zejména na analýzu textu. V posledních letech se staly klíčovou technologií v oblasti umělé inteligence, která zásadně mění způsob, jakým komunikujeme s počítači i mezi sebou.
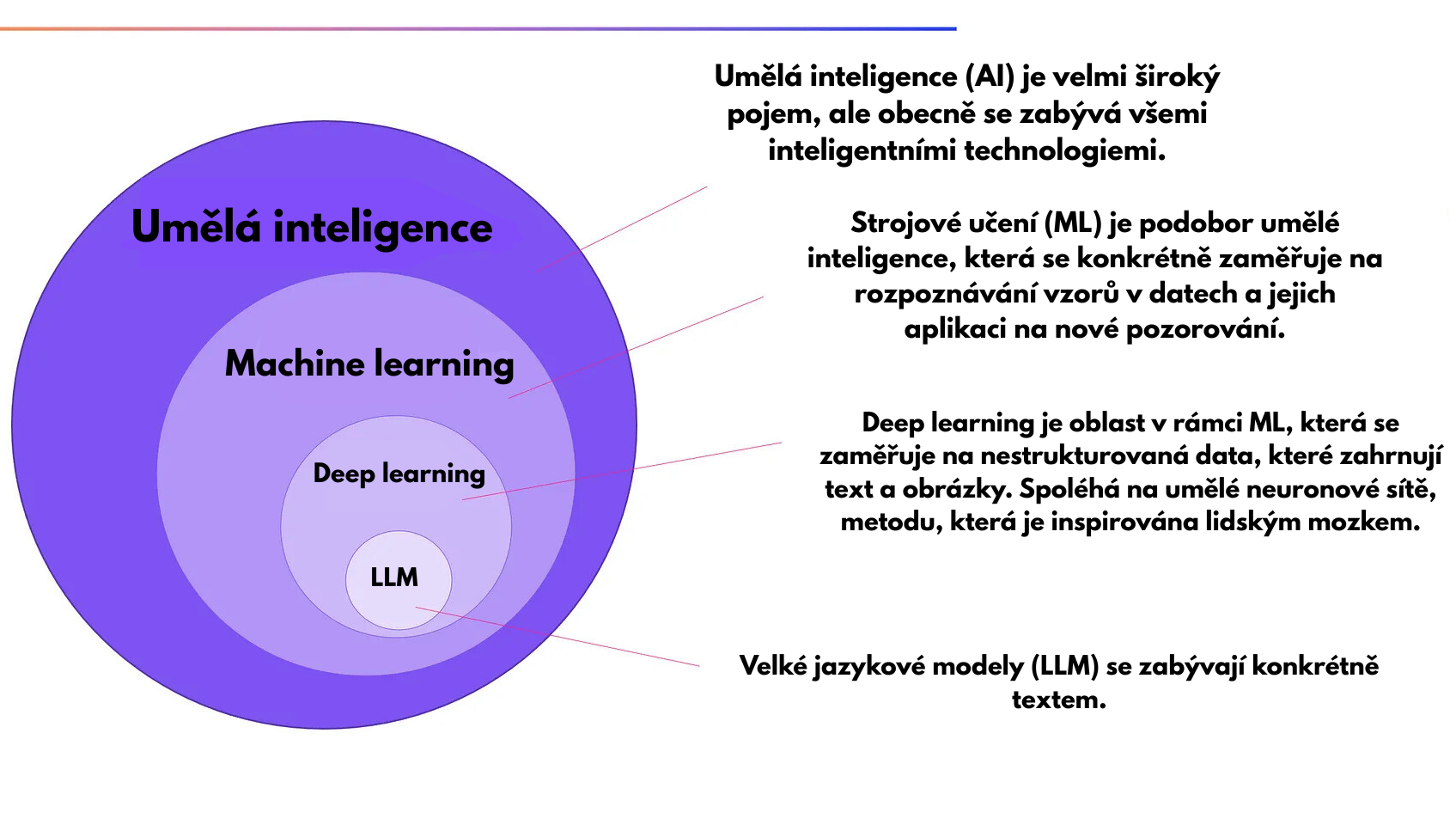
Jak fungují velké jazykové modely?
LLM jsou postaveny na hlubokých neuronových sítích, nejčastěji na architektuře zvané transformer. Tyto modely jsou trénovány na obrovských množstvích textových dat – často v řádu miliard až bilionů slov – která pocházejí z různých zdrojů, jako jsou knihy, webové stránky, články nebo diskuzní fóra. Během tréninku se model učí rozpoznávat jazykové vzory, gramatiku, význam slov, kontext, a dokonce i jemné nuance, jako je humor nebo sarkasmus.
Proces učení probíhá buď zcela bez dohledu (model se sám snaží pochopit strukturu jazyka), nebo částečně pod dohledem (model dostává od vývojářů správné odpovědi ke konkrétním úlohám). Díky tomu dokáže LLM generovat smysluplné a koherentní texty, odpovídat na otázky, shrnovat obsah, překládat mezi jazyky nebo vytvářet kreativní texty. Nedávno jsme psali o tom, jaká jsou rizika umělé inteligence. Zdá se, že nejvíce lidí se bojí toho, že jim vezme práci. Kdybyste se i vy poohlíželi po rekvalifikaci, vězte, že lidí, kteří budou trénovat jazykové modely, je vždy potřeba.

Důležité vlastnosti a schopnosti LLM
- Porozumění a generování textu: LLM dokážou nejen analyzovat a shrnovat existující texty, ale také vytvářet nové, smysluplné věty a odstavce, které působí velmi lidsky.
- Překlad mezi jazyky: Díky tréninku na vícejazyčných datech zvládají LLM překládat texty s překvapivou přesností a zachováním kontextu.
- Odpovídání na otázky: Modely mohou fungovat jako chatboti, kteří odpovídají na dotazy uživatelů a vedou s nimi konverzaci.
- Analýza sentimentu: LLM dokážou rozpoznat náladu a emoce v textu, což se využívá například v analýze zákaznických recenzí.
- Tvorba původního obsahu: Od článků přes básně až po programovací kód – LLM zvládají generovat obsah na základě krátkého zadání (promptu).
Příklady využití v praxi
- Chatboti a virtuální asistenti (např. ChatGPT, Google Bard)
- Automatizovaná zákaznická podpora
- Strojový překlad
- Generování marketingových textů a shrnutí dokumentů například pro copywritery
- Analýza sentimentu v recenzích a na sociálních sítích
- Návrh a generování programového kódu třeba v Pythonu, JavaScriptu nebo Ruby
Jaké jsou výhody a výzvy LLM
- Zrychlení a automatizace rutinních úkolů
- Zlepšení zákaznické zkušenosti díky personalizované komunikaci
- Schopnost zpracovat a analyzovat obrovské množství nestrukturovaných dat
Výzvy:
- Výpočetní náročnost: Trénink i provoz LLM vyžaduje velké množství výpočetních zdrojů a energie. Existují totiž i SML, small language models, například Google Gemma nebo MicrosoftPhi2, tedy modely, které vyjadřují výrazně méně výpočetní energie. Díky tomu jsou i rychlejší a hodí se v kontextech, kde potřebujeme odpověď v reálném čase.
- Etické otázky: Modely mohou neúmyslně šířit dezinformace, stereotypy nebo být zneužity ke generování škodlivého obsahu.
- Omezení v porozumění kontextu: I když LLM dokážou napodobit lidský jazyk, někdy nerozumí hlubšímu kontextu nebo generují tzv. „halucinace“ – smyšlené informace prezentované jako fakta.
- Riziko úniku citlivých dat: Modely mohou nechtěně generovat obsah obsahující části trénovacích dat, pokud nebyla data správně anonymizována.
- Neprůhlednost („black box“): Je obtížné vysvětlit, proč model generoval konkrétní odpověď.
Jak se trénují LLM?
Trénink LLM je komplexní proces zahrnující:
- Shromažďování a čištění dat – výběr kvalitních a různorodých textových zdrojů.
- Tokenizace – převod textu do číselné podoby, se kterou model pracuje.
- Vlastní trénink – model se učí předpovídat další slovo (nebo část textu) na základě předchozího kontextu.
- Ladění na konkrétní úkoly – model lze dále dolaďovat na specializovaných datech, např. pro právní, lékařské nebo technické použití.
Z toho vyplývá, že jde pouze o pravděpodobnostní modely, které nedokáží samy přemýšlet, zatím se to ale spíše učí, jako stroje. Oproti GAN jsou vhodnější spíše pro práci s textem, od toho je i označení “jazykový”. Také jim stále chybí hlubší porozumění, kreativita a schopnost adaptace na úrovni člověka, ale oproti tradičním algoritmům dokážou pracovat s mnohem širším kontextem a jazykovou variabilitou.
Existují ale i další modely, jako jsou:
Klasifikační modely (např. rozhodovací stromy, SVM, menší neuronové sítě), které rozpoznávají, do které kategorie daný vstup patří (např. spam/nespam).
Regresní modely, které předpovídají číselné hodnoty (např. cenu domu).
Konvoluční neuronové sítě (CNN), které se specializují na zpracování obrazových dat (např. rozpoznávání objektů na fotografiích).
Rekurentní neuronové sítě (RNN), které jsou vhodné pro práci s časovými řadami nebo sekvencemi (například předpověď počasí).
Jaká je budoucnost LLM
Velké jazykové modely se stále rychle vyvíjejí – stávají se multimodálními (umí zpracovávat nejen text, ale i obrázky, zvuk či video), zlepšuje se jejich schopnost „uvažovat“ a řešit složitější úlohy. S rostoucím výkonem a dostupností budou LLM čím dál více ovlivňovat podnikání, vzdělávání i každodenní život. Zároveň je však důležité řešit etické otázky a zajistit bezpečné a odpovědné používání těchto technologií. Neetické je zejména využívání fotografií cizích lidí k trénování modelů nebo taky autorských uměleckých děl.
Aktualizováno dne: 8. 7. 2025
Zdroje:
- Shaip.com [online]. [cit. 07. 07. 2025]. Dostupné z: https://cs.shaip.com/blog/a-guide-large-language-model-llm/
- Cloudflare: What is a Large Language Model? [online]. [cit. 07. 07. 2025]. Dostupné z: https://www.cloudflare.com/learning/ai/what-is-large-language-model/
- Co je LLM? Rychlý přehled jazykových modelů, funkcí a využití [online]. [cit. 07. 07. 2025]. Dostupné z: https://engeto.cz/blog/ai/co-je-llm-velke-jazykove-modely/