

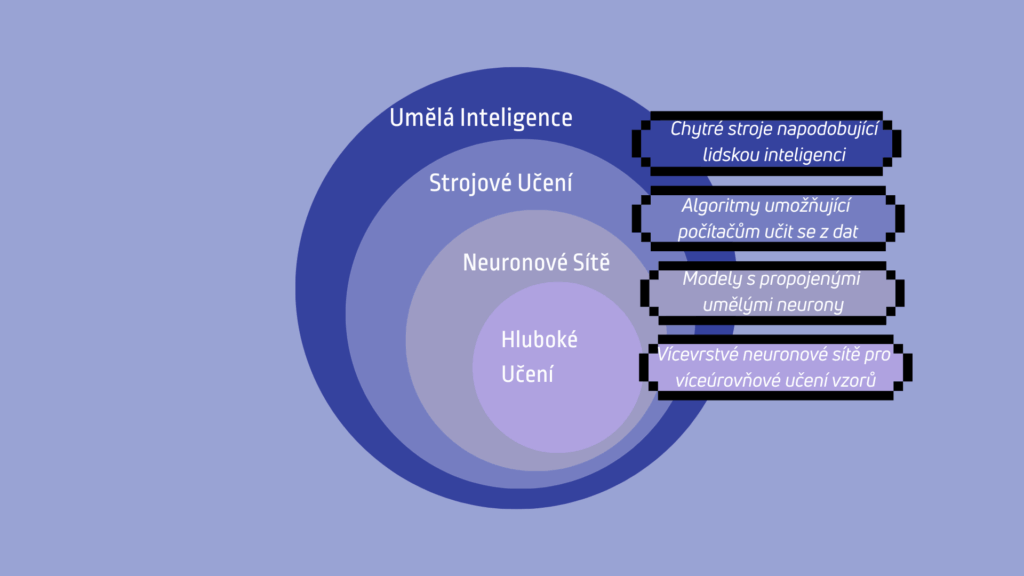
Strojové učení (machine learning, zkráceně ML) je jednou z nejdůležitějších technologií současného světa umělé inteligence. Umožňuje počítačům učit se z dat, zlepšovat se na základě zkušeností a automaticky generovat předpovědi nebo rozhodnutí, a to bez nutnosti přímého programování každého kroku.
Zatímco se může na první pohled zdát, že jde o technologii určenou jen pro datové analytiky nebo vývojáře, ve skutečnosti strojové učení potkáváme v běžném životě častěji, než si myslíme. Je součástí mnoha aplikací a služeb, umí například filtrovat spam, doporučovat další epizodu oblíbeného seriálu, detekovat podezřelé transakce na bankovním účtu a je také součástí prediktivních modelů ve zdravotnictví. V tomto článku si přiblížíme, co strojové učení skutečně je, jak funguje a kde všude se s ním můžeme setkat.
Co je strojové učení
Strojové učení je metoda analýzy dat, která umožňuje systémům „učit se“ z dostupných informací a na jejich základě dělat rozhodnutí či předpovědi bez toho, aby byly všechny možnosti předem naprogramovány.
Na rozdíl od tradičního programování, kde vývojář přesně definuje pravidla („pokud A, pak B“), strojové učení funguje tak, že algoritmus zpracuje velké množství dat, identifikuje vzorce a vztahy a podle nich se „naučí“, jak reagovat v podobných situacích. Čím víc kvalitních dat model získá, tím přesnější výsledky dokáže generovat.
Příklad strojového učení v praxi
Představte si aplikaci na rozpoznávání rukopisu. Místo toho, aby někdo ručně naprogramoval, jak vypadá každé písmeno ve všech variantách, algoritmus projde tisíce ukázek psaných rukou a „naučí se“, jak typicky vypadá například písmeno „a“. Pokud se s podobným stylem setká znovu, rozpozná ho s vysokou mírou jistoty.
Strojové učení je základní stavební kámen celé řady moderních technologií, od doporučovacích systémů na streamovacích platformách, přes autonomní řízení vozidel, až po pokročilé analýzy v lékařství či bankovnictví.
I běžní uživatelé dnes mohou pracovat s jazykovými modely, které fungují na základě strojového učení. V OCTODEEP si můžete vybrat mezi několika jazykovými modely, jako je například GPT-4.1, GPT-4, DeepSeek V3, Mistral Large, Gemini 2.0 Flash i Gemini 1.5 Pro, také modely z řady Claude i Grok.

Jak funguje strojové učení
Strojové učení funguje na procesu, který probíhá ve třech zásadních krocích.
Prvním krokem celého procesu je získání a příprava dat. Aby algoritmus mohl automatizovaně fungovat, potřebuje data, ze kterých se může učit, například tabulku s údaji o zákaznících a jejich nákupním chování.
Druhým krokem je trénink modelu. Model, který již získal potřebná data, je jim vystaven a hledá v nich vzorce a vztahy.
Posledním krokem je predikce a ověřování. Model nakonec aplikuje naučené poznatky na nová data a systém vyhodnocuje, jak přesně funguje.
Na základě toho, jaký typ dat a zpětné vazby model dostává, rozlišujeme tři základní druhy strojového učení.
Supervised learning
Model dostává vstupní data spolu se správným výstupem (např. „tento e-mail je spam/není spam“) a učí se na základě těchto příkladů. Příkladem může být rozpoznávání rukopisu, předpověď vývoje ceny akcií nebo kategorizace e-mailů.
Unsupervised learning
Model pracuje pouze se vstupními daty a bez označených výsledků hledá v datech vzory nebo skupiny. Například segmentace zákazníků podle nákupního chování nebo detekce anomálií v síťovém provozu.
Reinforcement learning
Model se učí metodou pokus-omyl na základě zpětné vazby z prostředí (odměna / trest) a optimalizuje svou strategii. Příkladem je třeba samořiditelné auto, jako Tesla.
Tyto přístupy tvoří základní rámec, na kterém jsou postaveny konkrétní algoritmy, které si více představíme v další části.

Obrázek vygenerovaný v AI modelu Photon v aplikaci OCTODEEP.
Nejčastější metody a algoritmy strojového učení
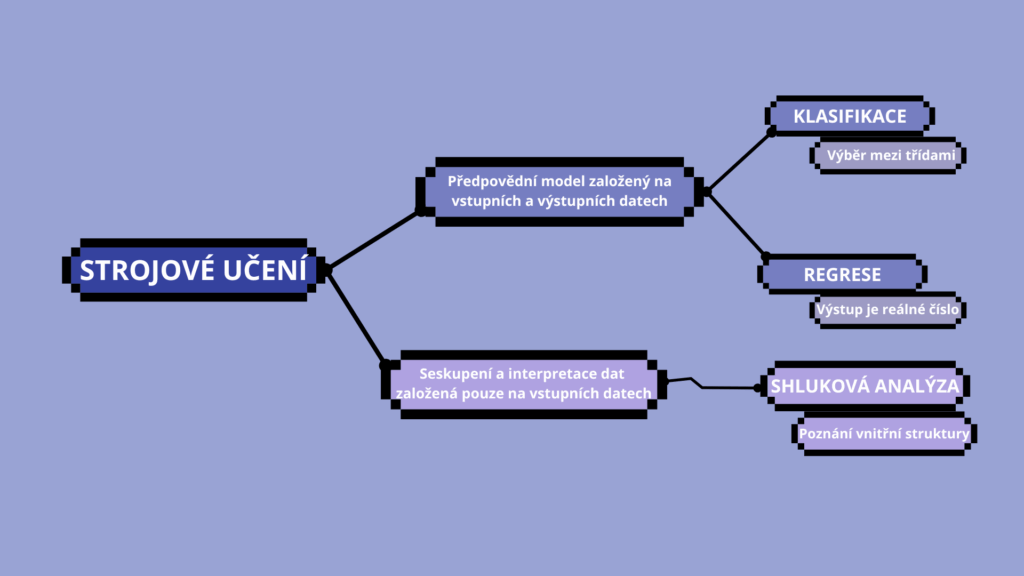
Za každým systémem strojového učení stojí konkrétní algoritmus, tedy matematický postup, podle kterého model zpracovává data, učí se z nich a vytváří predikce. Některé metody se hodí pro klasifikaci (přiřazování kategorií), jiné pro regresi (predikci číselných hodnot) nebo zjišťování skrytých struktur v datech.
Pokud vás zajímá, jak se umělá inteligence vyvíjela v průběhu let, podívejte se na náš článek Vývoj umělé inteligence.
Jedním z nejběžnějších přístupů je klasifikace, při které model přiřazuje vstupní data do předem daných kategorií. Například e-mailový filtr rozhoduje, zda je zpráva spam, nebo není. Banka může stejným způsobem hodnotit, zda je žádost o úvěr riziková. K tomu slouží algoritmy jako logistická regrese, rozhodovací stromy, náhodný les (random forest) nebo neuronové sítě. Výhodou klasifikace je její široká použitelnost a poměrně rychlé nasazení, i když při nevyvážených datech může docházet ke zkreslení.
Pro predikci spojitých číselných hodnot se používají regresní algoritmy. Ty na základě vstupních parametrů, například velikosti bytu, lokality a stáří, dokážou odhadnout jeho tržní cenu nebo predikovat denní prodej zboží podle ročního období a marketingových kampaní. Základním nástrojem je zde lineární regrese a její pokročilejší verze s regulací (ridge, lasso). Regrese je snadno interpretovatelná, ale je náchylná k nepřesnostem při složitějších vztazích v datech, vyžaduje tedy jejich dobrou přípravu.
Metoda shlukování (clustering)
Tam kde nejsou výstupní kategorie ani známé výsledky, nastupuje shlukování (clustering). To umožňuje dělit data do skupin podle vnitřní podobnosti bez jakéhokoli „návodu“. Typickým příkladem je rozdělení zákazníků podle nákupního chování nebo nové kategorizování nemocí podle symptomů a genetických dat. Mezi nejpoužívanější algoritmy patří K-means, hierarchické shlukování nebo DBSCAN. Clustering je ideální pro průzkumnou analýzu a odhalování skrytých souvislostí, i když výstupy nejsou vždy předvídatelné.
Rozhodovací stromy
Další zajímavou metodou strojového učení jsou rozhodovací stromy, které tvoří větvenou strukturu na základě jednoduchých otázek dojde ke klasifikaci nebo predikci. Pokud je těchto větvených struktur více a jejich výstupy se kombinují, vzniká tzv. náhodný les. Rozhodovací stromy využívá například pojišťovna k vyhodnocení rizikovosti klienta nebo e-shopy při doporučování produktů podle předchozích nákupů. Výhodou je rychlost a snadná interpretace výsledků, ale hrozí „přeučení” (overfitting), pokud model není správně nastavený. Méně vhodná je tato metoda pro velmi složité úlohy s nestrukturovanými daty.
Neuronové sítě
Nejsilnější a zároveň nejnáročnější skupinu tvoří neuronové sítě, které napodobují strukturu lidského mozku, skládají se z uzlů („neuronů”), které spolu komunikují a váží důležitost jednotlivých výstupů. Pokud se tyto sítě skládají z mnoha vrstev, mluvíme o tzv. deep learningu (hlubokém učení). Právě díky této hloubce jsou schopné zachytit velmi složité vzorce v nestrukturovaných datech, jako jsou obrazy, zvuk nebo přirozený jazyk. Právě díky neuronovým sítím dnes fungují systémy na rozpoznávání obličejů, hlasoví asistenti, jako Siri, automatické překladače a umělá inteligence zaměřená na generování obsahu jako je text, obraz i video. Konvoluční neuronové sítě se využívají především pro zpracování obrazu, rekurentní sítě zase pro práci s časovou posloupností (např. zvuk či text). Nejmodernější jazykové modely, jako je například GPT, DeepSeek, Mistral, Gemini atd. jsou postaveny na architektuře zvané transformery. Neuronové sítě dosahují skvělých výsledků, ale zároveň bývají „černou skříňkou“ jejich rozhodování je obtížně vysvětlitelné a výpočetně velmi náročné.
Jak už bylo výše zmíněno neuronové sítě nejsou jen nástrojem pro analýzu dat, ale dokážou tvořit i vizuální obsah. V OCTODEEP si můžete vyzkoušet generování obrázků pomocí modelů jako DALL-E 3, Stable Diffusion XL, GPT 1 Image, Grok 2 Image, Imagen a dalších.
Strojové učení napříč obory
Jedním z důvodů, proč je strojové učení považováno za technologii budoucnosti, je jeho univerzální použitelnost napříč odvětvími. Strojové učení dnes ovlivňuje zdravotnictví, finance, výrobu, školství i kulturu. Firmy i organizace si díky němu budují chytřejší systémy, které se adaptují, předvídají a rozhodují efektivněji než kdy dřív.
Ve zdravotnictví se modely strojového učení používají například k predikci diagnóz, odhalování rizikových pacientů nebo personalizaci léčby. Pomocí analýzy rozsáhlých zdravotnických dat dokážou odhalit vzorce, které by lidskému oku snadno unikly. Některé algoritmy dnes pomáhají s diagnostikou rakoviny na základě snímků z CT nebo MRI s přesností srovnatelnou s lidským specialistou.
Ve finančním sektoru je strojové učení hlavním nástrojem pro detekci podvodných transakcí, hodnocení bonity klientů a predikci tržních pohybů. Banky využívají klasifikační modely k tomu, aby automaticky rozpoznaly nestandardní chování na účtu nebo nastavily individuální úrokovou sazbu podle rizikového profilu klienta.
V průmyslu a výrobě se ML uplatňuje v oblasti prediktivní údržby, algoritmy sledují provozní data ze strojů a předvídají, kdy hrozí porucha. Tím se minimalizují výpadky a snižují náklady na servis. Také v logistice pomáhá strojové učení optimalizovat trasy, řídit skladové zásoby nebo předvídat zpoždění dodávek.
Výrazné uplatnění nachází ML také v marketingu a e-commerce, kde modely analyzují chování zákazníků a pomáhají s personalizací obsahu. Doporučovací algoritmy, jaké známe třeba z Netflixu nebo Spotify, fungují právě díky strojovému učení. E-shopy mohou díky těmto technologiím přesněji cílit reklamu, optimalizovat ceny nebo zvyšovat míru konverze.
V oblasti dopravy a autonomní mobility strojové učení řídí samořiditelná auta, učí je vnímat okolí a rozhodovat se v reálném čase. Podobné principy pak využívají i moderní navigační systémy, které předpovídají dopravní situaci nebo doporučují ideální trasu na základě aktuálních podmínek.
Ve školství se strojové učení objevuje stále častěji, a to nejen na straně vzdělávacích institucí, ale i samotných studentů. Univerzity využívají analytické modely k predikci studijní úspěšnosti, detekci plagiátorství nebo k personalizaci výuky v online kurzech. Na druhé straně si studenti stále častěji pomáhají ML nástroji při psaní bakalářské práce, rešerší, referátů, slohovek i seminární práce. Modely, které rozumí textu, dokáží navrhnout strukturu, shrnout odborné zdroje nebo vygenerovat návrh textu na základě klíčových bodů. I díky tomu se z umělé inteligence stává běžná studijní pomůcka, podobně jako kdysi kalkulačka nebo textový editor.
Jestliže byste se chtěli dozvědět, jak efektivně využít umělou inteligenci pro psaní závěrečné práce, můžete se podívat na článek Psaní bakalářské práce pomocí umělé inteligence.
Strojové učení se využívá i třeba v zemědělství, kde pomáhá monitorovat úrodu, předvídat výskyt škůdců nebo optimalizovat zavlažování.
Tato široká aplikovatelnost strojového učení ukazuje, že se tato technologie může stát součástí téměř jakéhokoli oboru, pokud má dostatek dat a dobře definovaný cíl.

Obrázek vygenerovaný v AI modelu Imagen v aplikaci OCTODEEP.
Výzvy a omezení strojového učení
Ačkoliv strojové učení otevírá obrovské možnosti, není bez rizik a slabin. Abychom mohli tuto technologii využívat zodpovědně a efektivně, je třeba porozumět jejím omezením a nevýhodám.
Jedním z hlavních předpokladů úspěchu ML modelu je dostatek kvalitních dat. Pokud jsou data neúplná, nevyvážená nebo zastaralá, algoritmus se učí chybně a výsledky mohou být zavádějící. Například systém, který byl trénován pouze na určitý typ klientů, může nespravedlivě diskriminovat jiné skupiny. To je problém známý jako bias (zkreslení dat), který může vést k neetickým nebo nežádoucím rozhodnutím.
Dalším úskalím je přeučení (overfitting), kdy se model naučí data až příliš dobře – včetně jejich šumu a chyb. Takový model pak funguje skvěle na trénovacích datech, ale selhává při nasazení v praxi. Naopak podtrénovaný (underfitted) model může být příliš jednoduchý a nepostihne složitější souvislosti.
Velkou výzvou je také vysoká výpočetní náročnost, zejména u hlubokých neuronových sítí. Trénink velkých modelů vyžaduje výkonné grafické karty, servery a značné množství energie. To má nejen technické, ale i ekologické důsledky.
Zásadní je rovněž otázka transparentnosti a interpretovatelnosti. Zatímco jednodušší algoritmy (např. rozhodovací stromy) lze snadno vysvětlit, komplexní modely, jako jsou hluboké neuronové sítě, se často chovají jako tzv. „černá skříňka“. Uživatel tak může získat výsledek bez toho, aby pochopil, proč k němu model dospěl. V některých odvětvích, například ve zdravotnictví nebo v právu, je to problém nejen etický, ale i legislativní.
V neposlední řadě je třeba zmínit etické a právní otázky. Kdo nese odpovědnost za rozhodnutí přijaté na základě ML modelu? Může algoritmus porušit lidská práva? Jak zajistit ochranu osobních údajů? Tato témata jsou dnes čím dál aktuálnější a vyžadují nejen technologické, ale i společenské a právní řešení.
Strojové učení je bezpochyby mocný nástroj, ale jako každý nástroj vyžaduje správné zacházení. A právě uvědomění si jeho limitů je prvním krokem k odpovědnému a smysluplnému využití.
Aktualizováno: 26. 6. 2025
Zdroje:
Rascasone [online]. [cit. 26. 06. 2025]. Dostupné z: https://www.rascasone.com/cs/blog/strojove-uceni-ml-metody-klasifikace#co-je-strojov-eacute-ucen-iacute-machine-learning
Co je strojové učení? | Microsoft Azure [online]. [cit. 26. 06. 2025]. Dostupné z: https://azure.microsoft.com/cs-cz/resources/cloud-computing-dictionary/what-is-machine-learning-platform