

Stable Diffusion je jedním z nejpokročilejších modelů pro generování obrazů, který přináší revoluční možnosti v oblasti umělé inteligence. Tento open-access difuzní model umožňuje vytvářet realistické a detailní obrázky na základě textových popisů, čímž otevírá dveře k novým kreativním použitím. Díky své flexibilitě a dostupnosti se stal oblíbeným nástrojem nejen mezi vývojáři, ale i umělci a designéry. V tomto článku se podíváme na principy jeho fungování, jeho výhody a možnosti, které přináší do světa generativního umění. Poslední verzí tohoto modelu je Stable Diffusion XL, která má větší neuronovou síť U-Net a dokáže generovat ještě kvalitnější snímky. Právě ten si můžete vyzkoušet v naší aplikaci OCTODEEP.

Stable Diffusion je unikátní v tom, že dokáže generovat vysoce kvalitní snímky s vysokou mírou kontroly nad výstupem. Může vytvářet výstup pomocí různých vstupů s popisným textem, jako je styl, rámeček nebo předvolby. Kromě vytváření obrázků může SD přidávat nebo nahrazovat části obrázků díky inpainting a rozšíření velikosti obrázku, tzv. outpainting.
Namísto provozu ve vysokorozměrném obrazovém prostoru Stable Diffusion nejprve komprimuje obraz do latentního prostoru. Model pak postupně ničí obraz přidáváním šumu a je trénován, aby tento proces zvrátil a obraz regeneroval od začátku.
Stable Diffusion je open source. Pokud máte hardware a potřebné znalosti Pythonu, můžete si stáhnout a spustit offline verzi modelu zdarma, bez jakýchkoli omezení. Pokud ne, můžete ho začít používat zdarma z jejich webových stránek, po čase po vás ale budou chtít dokoupit další kredity. Další možností je naše aplikace OCTODEEP, kde si můžete vybrat tarif s množstvím kreditů, které vám vyhovuje.
Top vlastnosti
- Pokročilé vylepšení obličeje: Pomocí funkce Adetailer můžete obličeje perfektně restaurovat.
- Lepší schopnosti barvení: Pomocí nástroje ControlNet můžete efektivněji přebarvovat (inpainting funkce) třeba barvu šatů vaší modelky, aniž by se obarvilo cokoli jiného.
- Vysoká kvalita výstupů: Model je schopen generovat obrázky s vysokým rozlišením a detailností, zejména ve verzích jako SDXL (Stable Diffusion XL), která podporuje rozlišení až 1024×1024 pixelů.
- Open-source přístup: Stable Diffusion je open-source projekt, což znamená, že komunita má přístup k modelu, může jej upravovat, vylepšovat a vytvářet vlastní verze.
- Nízké hardwarové nároky: Na rozdíl od některých jiných generativních modelů (např. DALL-E) je Stable Diffusion optimalizován tak, aby mohl běžet i na běžných grafických kartách, což jej činí dostupnějším.
Využití techniky LoRA
LoRA (Low-Rank Adaptation) je technika používaná v oblasti strojového učení, zejména při trénování velkých jazykových nebo obrazových modelů, jako jsou Stable Diffusion nebo GPT. Tato metoda umožňuje efektivní přizpůsobení (fine-tuning) již předtrénovaných modelů na nové úlohy nebo specifická data, a to s výrazně nižšími výpočetními nároky a menším množstvím trénovacích dat. To znamená:
Nízkodimenzionální přizpůsobení:
- Místo toho, aby se upravovaly všechny parametry velkého modelu (což je výpočetně náročné), LoRA přidává malé množství parametrů, které jsou trénovány samostatně.
- Tyto nové parametry jsou reprezentovány jako nízkodimenzionální matice, což snižuje počet potřebných výpočtů.
Zachování původního modelu:
- Původní model zůstává nezměněn, což znamená, že LoRA nevyžaduje kompletní retrénování modelu.
- Přidané parametry se kombinují s původními během inferenčního procesu.
Efektivita:
- LoRA umožňuje rychlé a levné přizpůsobení modelu na specifické úkoly nebo datové sady, aniž by bylo nutné mít přístup k obrovským výpočetním zdrojům.
Kde se LoRA používá?
- Obrazové modely: Například při přizpůsobení modelů Stable Diffusion pro generování specifických stylů, postav nebo témat.
- Jazykové modely: Pro přizpůsobení velkých jazykových modelů, jako je GPT, na konkrétní domény nebo úlohy.
- Personalizace: LoRA umožňuje snadno přizpůsobit modely pro individuální potřeby uživatelů.
LoRA je tedy velmi užitečná technika, která usnadňuje práci s velkými modely a umožňuje jejich efektivní využití i v prostředích s omezenými zdroji.
Modely Stable Diffusion
Modely ve Stable Diffusion představují konkrétní verze nebo varianty trénovaných neuronových sítí, které jsou schopné generovat obrázky na základě textového zadání (text-to-image). Každý model je výsledkem trénování na specifické datové sadě a má určité vlastnosti, schopnosti a omezení. Stable Diffusion obsahuje spoustu oficiálních modelů vytvořených vývojáři (anime styl, gothic atd.), další možnost je využití modelů vytvořených komunitou pomoci technik jako je finetuning nebo již zmíněná LoRA. Více o vytváření modelů se můžete dočíst zde.
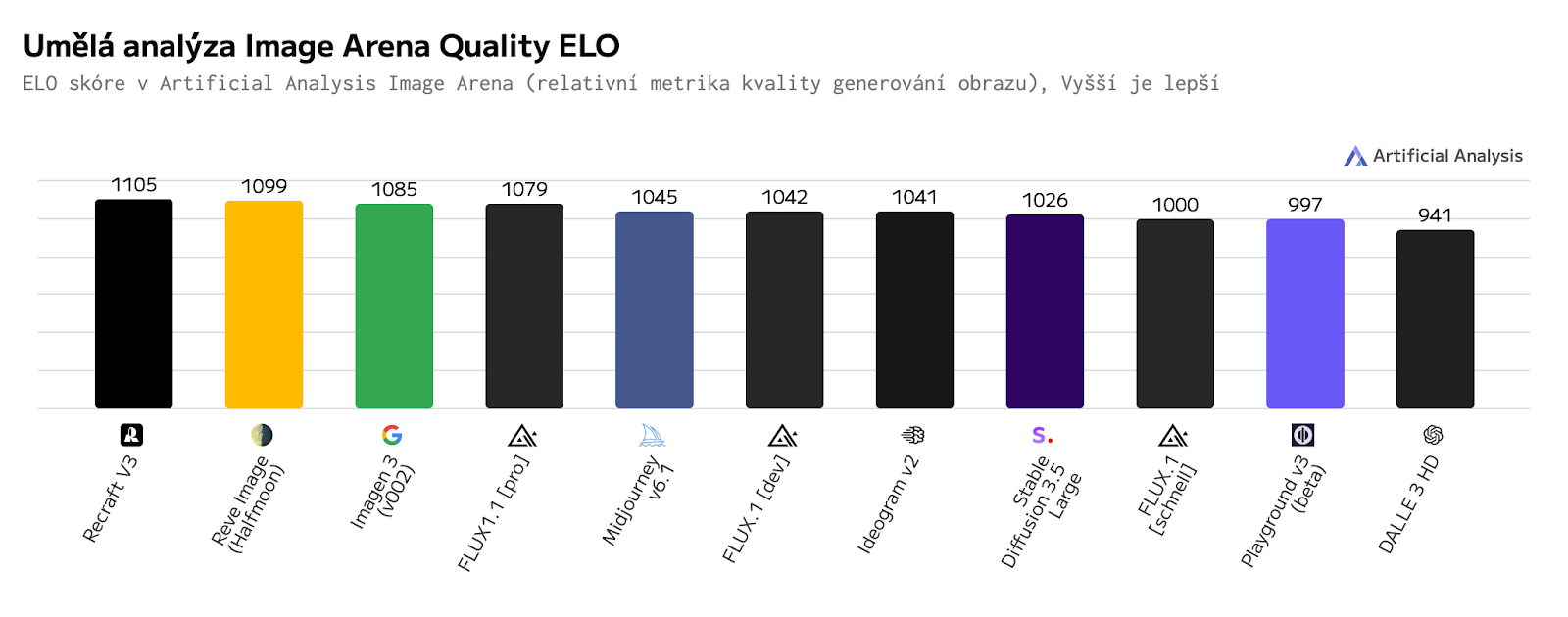
Porovnání s ostatními grafickými modely
Zde si můžete prohlédnout, jak je na tom Stable diffusion v kvalitě obrázků ve srovnání s jinými modely.
Posun ke Stable Diffusion 2
Stable Diffusion je technologie, která dokáže generovat obrázky na základě textového popisu. Aby to fungovalo, potřebuje systém, který rozumí textu a dokáže ho propojit s obrázky. V první verzi Stable Diffusion se používal model CLIP, který byl sice volně dostupný, ale data, na kterých se učil, byla tajná. To znamená, že nikdo přesně neví, jaká data ovlivnila jeho schopnosti.
Ve druhé verzi Stable Diffusion se místo toho používá OpenCLIP, což je podobný model, ale trénovaný na veřejně známých datech. Tato data byla navíc vybrána tak, aby neobsahovala nevhodné (NSFW) obrázky. Díky tomu je nový model nejen transparentnější (víme, na čem se učil), ale také vytváří kvalitnější obrázky, například lepší strukturu kůže u lidí.
Zvětšování rozlišení pomocí difúzních metod
Stable Diffusion 2.0 také obsahuje model Upscaler Diffusion, který zvyšuje rozlišení obrázků faktorem 4. Níže je příklad našeho modelu převzorkování obrázku generovaného v nízkém rozlišení (128×128) na obrázek s vyšším rozlišením (512×512). V kombinaci s našimi modely převodu textu na obrázek dokáže Stable Diffusion 2.0 generovat obrázky s rozlišením 2048×2048 – nebo dokonce vyšším.

Model difúze hloubky obrazu
Nový model Stable Difuser s hloubkovým vedením, nazvaný depth2img , rozšiřuje předchozí funkci image-to-image z verze 1 o zcela nové možnosti pro kreativní aplikace. Depth2img odvodí hloubku vstupního obrázku (pomocí existujícího modelu) a poté vygeneruje nové obrázky pomocí textu i informací o hloubce.

Jaké jsou rozdíly mezi modely Stable Diffusion?
| Model | Rok vydání | Hlavní vlastnosti | Výhody | Nevýhody |
| Stable Diffusion 1.5 | 2022 | Základní model pro generování obrázků z textu. | Široká dostupnost, nízké hardwarové nároky, komunita vytvořila mnoho vylepšení díky technice LoRA. | Nižší kvalita detailů, problémy s generováním realistických rukou a textu. |
| Stable Diffusion 2.1 | 2022 | Vylepšená verze s lepšími detaily a přesností. | Lepší kvalita obrázků než verze 1.5, stále relativně nízké hardwarové nároky. | Stále omezená fotorealističnost, problémy s textem a složitými detaily. |
| Stable Diffusion XL (SDXL) | 2023 | Nejnovější model s vysokým rozlišením (1024×1024 px) a fotorealistickými detaily. | Výrazně lepší kvalita obrázků, realistické obličeje, čitelný text, lepší kompozice a detaily. | Vyšší hardwarové nároky, pomalejší generování, méně dostupných vyladěných modelů . |
Omezení Stable Diffusion AI
Přestože umělá inteligence Stable Diffusion vykazuje výjimečné možnosti generování obrazu, má některá omezení, včetně:
Kvalita obrazu – Model byl trénován na obrázcích v různých rozlišeních a dokáže generovat obrázky až do rozlišení 1024×1024. Zatímco 512×512 je běžné rozlišení, možnosti modelu přesahují toto jediné rozlišení. Vyšší nebo nižší rozlišení mohou vykazovat určité rozdíly v kvalitě, ale model není striktně omezen na jediné vstupní nebo výstupní rozlišení.
Nepřesnosti – Nedostatečná a nekvalitní tréninková data lidských končetin mají za následek anatomické anomálie při pobízení modelu ke generování lidí. Generované končetiny, ruce a obličeje často obsahují nerealistické proporce nebo deformace, které prozrazují nedostatek reprezentativních rysů končetin v souborech dat.
Omezení přístupnosti – Navzdory demokratizaci přístupu ke všem vyžaduje přizpůsobení Stable Diffusion pro nové případy použití zdroje, které jsou pro většinu jednotlivých vývojářů nedostupné. Přetrénování specializovaných datových sad vyžaduje GPU s vysokou VRAM přesahující 30 GB, což spotřebitelské karty nedokážou dodat. To brání přizpůsobeným rozšířením přizpůsobit model jedinečným potřebám.
Předsudky – Vzhledem k tomu, že model byl převážně trénován na anglických dvojicích text-obrázek, které většinou reprezentují západní kultury, Stable Diffusion ze své podstaty posiluje tyto zakořeněné demografické perspektivy. Vygenerované obrázky udržují předsudky postrádající rozmanitost, zatímco jsou výchozí pro západní typy kvůli absenci multikulturních tréninkových dat.
Jazyková omezení – Generativní modely, jako je Stable Diffusion, mohou mít různé schopnosti interpretovat a generovat obrázky z výzev v různých jazycích, což závisí na jazykové rozmanitosti trénovacích dat.
Zobrazení celebrit – U Stable Diffusion 2 je překvapivě horší zobrazení celebrit, než u Stable Diffusion 1, jelikož tréninková data obsahovala méně obrázků celebrit. To může souviset s omezením možností zobrazit celebrity v nelichotivých pozicích, které se nachází v etickém kodexu většiny AI nástrojů.
Aktualizováno dne: 25. 4. 2025
Zdroje:
- Stable Diffusion Online [online]. [cit. 09. 04. 2025]. Dostupné z: https://stablediffusionweb.com/
- Text to Image Models and Providers Leaderboard | Artificial Analysis [online]. [cit. 09. 04. 2025]. Dostupné z: https://artificialanalysis.ai/text-to-image#speed
- Stable Diffusion 1 vs 2 – What you need to know [online]. [cit. 09. 04. 2025]. Dostupné z: https://www.assemblyai.com/blog/stable-diffusion-1-vs-2-what-you-need-to-know
- Professional AI Image Generation with Precision | Diffus [online]. [cit. 09. 04. 2025]. Dostupné z: https://www.diffus.me/
- Stable diffusion 2.0 [online]. [cit. 09. 04. 2025]. Dostupné z: https://stability.ai/news/stable-diffusion-v2-release